Bulkheads 31 Dec 2009
Bulkheads are used in ships to create seperate watertight compartments which serve to limit the effect of a failure – ideally preventing the ship from sinking. The bold vertical lines in Samuel Halpern’s diagram illustrate them:
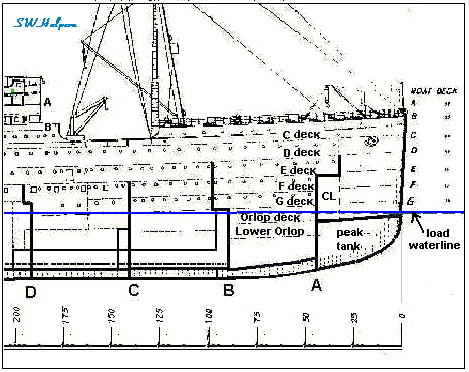
If water breaks through the hull in one compartment, the bulkheads prevent it from flowing into other compartments, limiting the scope of the failure.
This same concept is useful in the architecture of large systems for the same reason – limiting the scope of failure.
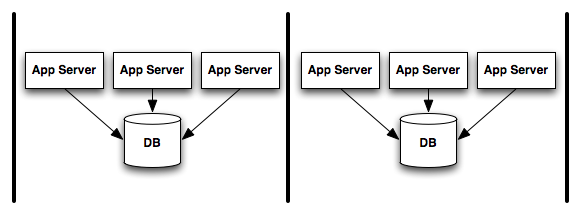
If we look at a very simple system, say something that easily partitions by user, like a wish list of some kind. We can put bulkheads in between sets of app servers talking to distinct databases. In this system a given app server only talks to the database in its partition.
Given this setup, if a single app server goes berserk and starts lashing out with a TCP hatchet at everything it talks to, no matter how angry it gets it only takes out a vertical slice of the system, the rest goes about business happily.
If we take a slightly fancier system (ie, slightly more realistic) we can see we develop (mostly) identical vertical slices:
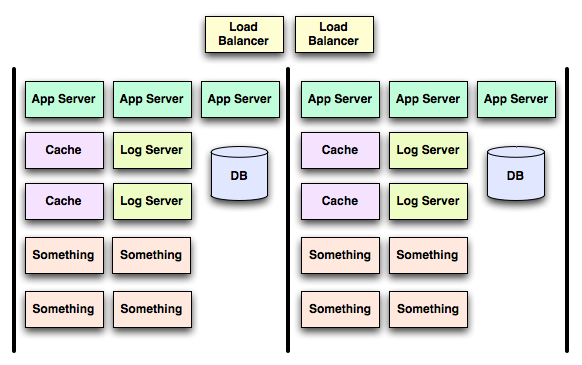
On a ship we’d call the groups compartments, but we’ll call them clusters because each vertical bunch of stuff forms a logical unit which can be thought of as one thing (say, a cluster!). In this setup, if one of the caches started blackholing requests the damage done (hopefully just latency increasing a small bump to a reasonable timeout) would stop at the bulkheads around the cluster. Yea!
If we look closely at the slightly fancier system, we note that a cluster consists of:
- 3 App Servers
- 2 Caches
- 2 Log Servers
- 4 Somethings
- 1 Database
Typically, you can use clusters as units by which to add capacity, and the exact contents of the cluster will be determined by finding the limiting element (usually the one which needs to maintain lots of state), on the most constrained axis of scale embodied in the cluster, and sizing out the rest of the elements based on their capacity relative to the limiting element. Add to this enough capacity to handle spikes, provide acceptable redundancy, and voila, you have a cluster. In theory.
In practice, some things simply do not work well with hard boundaries like this. In this example, note that the load balancers are not part of a cluster, but span clusters – they need to as they are responsible for determining which cluster can handle a given request!
It gets worse, notice that we have two log servers per cluster. Given a reasonable number of clusters, say 25, that amounts to 50 log servers. A single log server (in this case) is capable of servicing about 1000 app servers, but logs are really important so we need to run them redundantly, hence two per cluster. Given 25 clusters and three app servers per cluster, a single log server has plenty of capacity, yet we have 50 for fault isolation in this setup. The accountants are not happy.
Another variant on the inefficieny problem are the Somethings. Somethings utilization is very bursty. Under average conditions one is enough for each cluster, but they occasionally (once a week or so) burst to four times that activity, so we have four, in each cluster. Now, we know the usage pattern is such that bursts don’t overlap, so we’d really like to have shared burst capacity rather than per-cluster, but that will then breach the bulkhead.
This leads to system classification based upon the scope of failure directly causable by a given component (how is that for absract sounding?). If we revise our system to make the accountants and engineers happier (centralized things are generally easier to build) it might look like this:
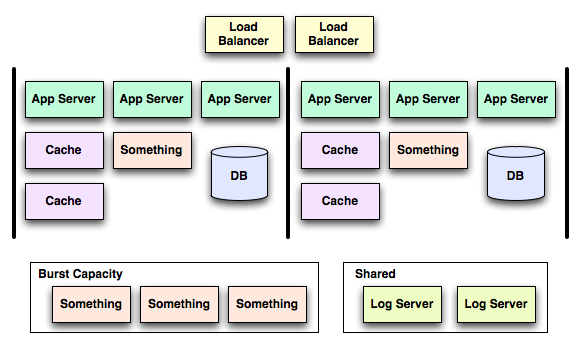
The system is now much more efficient, but we have increased the risk of a cascading failure taking down more, or all, of the system if any of the load balancers or log servers are effected, or if two something’s burst at the same time (I am sure you have heard someone say, “but that can never happen!” before, right?).
We’ll call services which span clusters Class A services, and services are fully contained within a cluster Class B services. Working with Class A services is harder than Class B because you need to be extra special super really really careful that the Class A service cannot take down your Class B service.
A famous example, going back to the naval usage of bulkhead, of a Class A service would be the passenger decks (the E deck in particular) on the Titanic.

The Titanic was built to suffer failure in a number of its clusters^W compartments, but in fact it suffered failure in too many, and the cluster spanning passenger decks allowed the water to cascade across bulkheads, leading to tragedy.